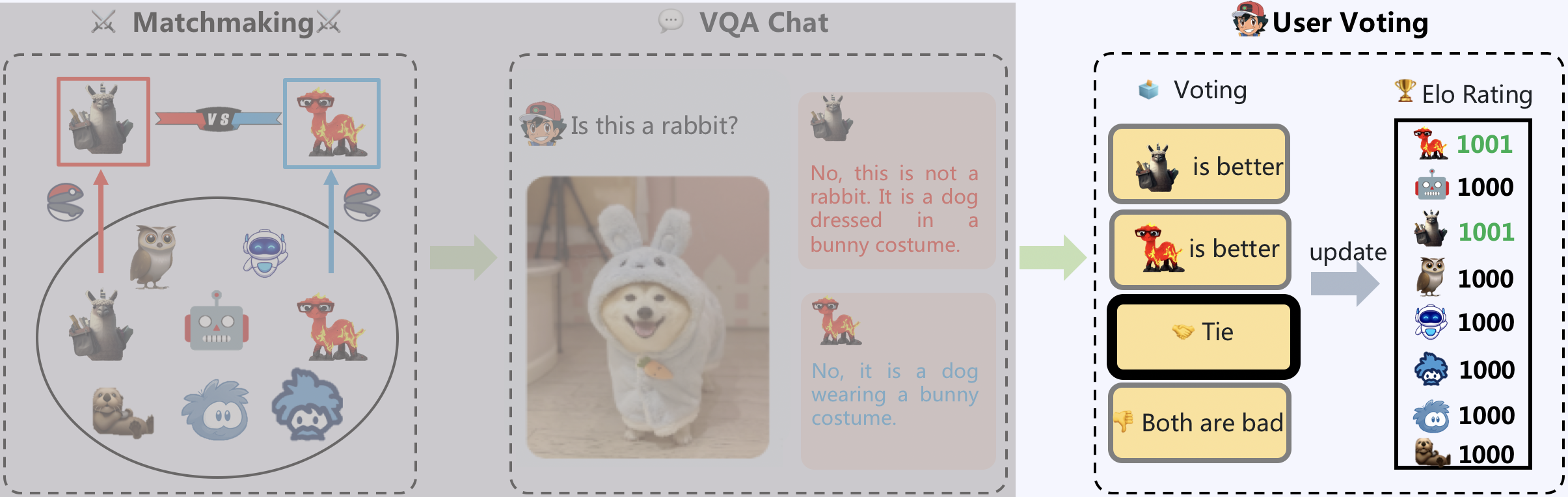
Multimodal Arena
Multimodal Arena, comprising three primary components: Matchmaking, VQA Chat, and User Voting. Initially, two models are sampled from the model zoo. Users then converse side-by-side with the models, who remain anonymous. Subsequently, users vote for the superior model.
Matchmaking
The Multimodal Arena comprises eight exemplary LVLM models, namely BLIP2, LLaVa, LLaMA-Adapter V2, MiniGPT-4, mPLUG-Owl, Otter, InstructBLIP, and VPGTrans. The matchmaking module employs a tournament-style random sampling approach to select two models. This sampling method guarantees that each pair of models is evaluated equitably. To ensure a fair comparison, the identities of both models are kept anonymous before user voting.
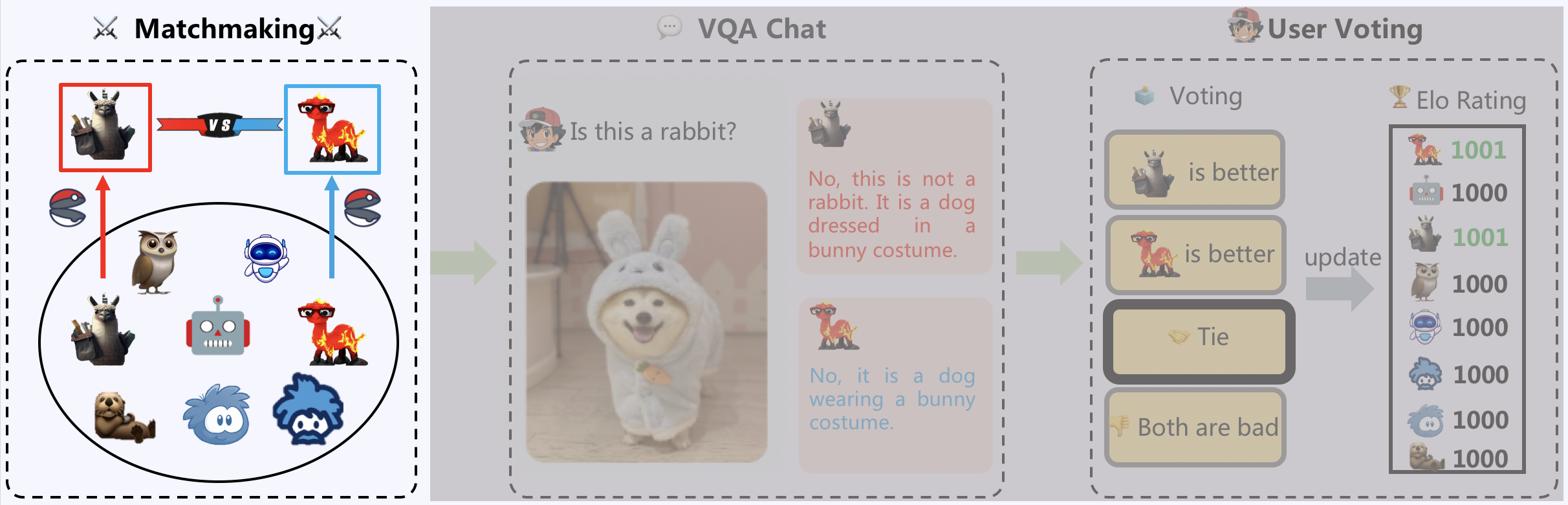
VQA Chat
Two models sampled in the matchmaking stage are asked to answer a question given visual input. To facilitate fast VQA chat, two approaches are implemented. Firstly, the user can manually input a question based on the visual input. This allows the user to inquire about specific points of interest. Secondly, a random question generator is instantiated with ChatGPT. This generator is capable of producing appropriate questions based on the images provided in the visual gallery.

User Voting
Following the chat session, users are requested to vote for their preferred model, with four available options: Model A, Model B, Tie, and Both are bad. After the voting process, the identities of the models are revealed. The use of anonymous pairwise battles facilitates a fair comparison of LVLM models at the user level. Voting results are subsequently used to update the Elo rating. The winning model will receive a positive score, while the score of the losing model is reduced.